
TL;DR: Following a three-phase forensic analysis methodology, we have developed a forensic analysis environment for instant messaging applications made up of two tools: one of them is responsible for extracting the content of a process that runs on a Windows system, while the another focuses on studying the information present in the process memory of an instant messaging application. Both tools work together, but can be used independently. Its source codes are released under the GNU/GPLv3 license and can be accessed at here and here, respectively. As a case study, in this work we focus on the Telegram application for Windows systems called Telegram Desktop. This post is a brief summary of our recently accepted paper in DFRWS EU 2022, “Extraction and analysis of retrievable memory artifacts from Windows Telegram Desktop application”.
Introduction
Instant messaging (IM) applications allow us to communicate quickly and easily. Today, a large part of society makes use of these applications to have text, audio, or even video conversations on a daily basis. Unfortunately, the misuse of IM apps allow cybercriminals to utilize them for malicious purposes (such as harassment, extortion, or fraud, to name a few). Therefore, the forensic analysis of IM applications can help provide essential clues to solve or clarify a possible crime.
The digital artifacts of interest in IM applications are, among others, the sent/received messages or the contacts. Some of these artifacts are securely stored in a database using encryption, which protects the confidentiality of data against attackers who have physical access to the devices. Likewise, IM application communications are typically established using end-to-end encryption, which also ensures data confidentiality against network attacks. Therefore, digital storage forensics fails to provide evidence. To overcome this, the running IM application can be used to obtain evidence, as the encrypted data must be decrypted when the application needs to use it. However, the application could be blocked, preventing access and making recently viewed data inaccessible. Furthermore, the data deleted by the user is not accessible through the GUI. Hence, memory forensics becomes especially interesting for working with IM applications to get even more evidence.
With the exponential growth of IM applications and the emergence of smartphones, many researchers have shown big interest in investigating IM applications on mobile platforms to acquire evidences for forensic analysis. However, little attention has been paid to desktop platforms.
To fill this gap, we focus on the forensic analysis of IM applications for desktop platforms, and, in particular, for the Windows operating system, which at the time of this writing is the predominant operating system on the market worldwide. In this regard, we follow an analysis methodology on which we then build an analysis environment for IM applications that can be easily extended for forensic practitioners and researchers to improve their analysis capabilities. To show its practicability, we study in detail the memory artifacts that can be extracted from the Telegram Desktop application.
Telegram is a multi platform IM service with client-server architecture. Currently, there are official Telegram clients for the most used operating systems both at the desktop (Windows, GNU/Linux, macOS) and mobile level (Android, iOS). Additionally, Telegram can also be used via web browser. Telegram applications can generally be locked with a password so that the user must enter it when accessing the application. This prevents an unauthorized person who physically seizes a device from being able to access the app without knowing the password. As of October 2021, Telegram is one of the 5 most popular instant messaging platforms globally.
Methodology
The memory artifact analysis methodology that we followed has three phases. The first phase (extraction phase) is dedicated to obtaining the memory content of the virtual address space of any process into appropriate files for analysis. The second phase (analysis phase) deals with the analysis of the data extracted in the previous phase, obtaining representative objects from the dumped files. Finally, the third phase (reporting phase) focuses on generating a report containing relevant information on all analyzed memory artifacts, such as the number of conversations, the number of messages, and other statistics.
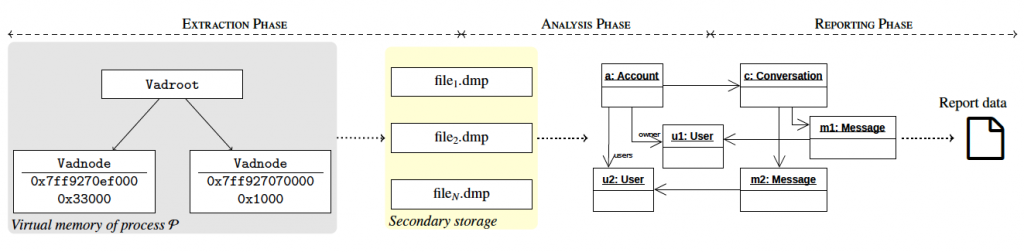
Each of these phases is supported by command line tools, facilitating integration into broader analysis pipelines. In particular, we have developed a tool (dubbed Windows Memory Extractor) for the extraction phase and another tool (dubbed IM Artifact Finder) for the analysis and reporting phases. Furthermore, this latest tool has been designed to support any IM service following the best software engineering practices. Both tools are freely and publicly available under the GNU/GPLv3 license, so forensic analysts and law enforcement agencies can use them while the forensic community can contribute by adding the support for different IM applications.
Extraction Phase
To analyze the memory of a process or an image, we must first dump it to disk. Also, we need to be able to navigate through the virtual addresses of the dumped memory contents. After exploring other existing tools for dumping Windows processes (like ProcDump or Process Hacker), we couldn’t find any tool that would facilitate programmatic navigation through virtual addresses of the dumped process. To solve this problem, we developed Windows Memory Extractor as a C++ command line tool to facilitate its deployment in any analysis workflow.
Windows Memory Extractor can dump all memory regions of a process into files, simply by specifying the process identifier of interest. The tool accepts an optional argument to specify the protections of the memory regions to extract. In addition, it also accepts another optional argument to specify the name of a process module when it is only necessary to extract the memory regions corresponding to that module.
The tool saves memory regions in separate files with the extension dmp in a directory named PID_Day-Month-Year_Hour-Minute-Second_UTC to clearly identify each dump. The nomenclature of these files includes the starting virtual address and the size of the memory region dumped, separated by an underscore. Obtaining these files for all the memory space of the process allow us to navigate through the virtual addresses of the dumped process, since we can pass from an object A that points to an object B simply by calculating the appropriate file that contains the virtual memory address of B and accessing it with the appropriate offset to locate such object.
This tool allows us to create memory dumps with fine-grained precision, which are necessary to extract memory artifacts from the process memory. In our particular case, we have used Windows Memory Extractor to generate memory dumps of processes related to IM applications running on a Windows system. In such memory dumps, we are particularly interested in the memory regions that do not have execute permissions, because those are the memory regions in which data such as messages, contacts, or user account information is stored.
Analysis Phase
IM Artifact Finder is a Python tool designed as a framework for obtaining memory artifacts from a dump of an IM application process. This tool can be used as a command line tool or as a library, making it easy to use and integrate into other forensic analysis pipelines. IM Artifact Finder is designed to work independently of a specific IM platform, operating system, or device. In this sense, the framework can be extended to support any IM application available for different operating systems and devices.
The memory artifacts obtained with IM Artifact Finder depend on each IM application and thus, when extending the framework to a new IM application, a prior reverse engineering task is needed to understand how the application stores its data in memory and when it is present.
When the IM application is proprietary and there is no source code available, the reverse engineering task is error prone and time consuming, making analysis much more difficult. Fortunately, when the IM application is open source, we can analyze its source code and use software engineering best practices to recreate the application design. For instance, we can recreate the Unified Modeling Language (UML) class diagram and UML sequence diagrams to represent the static and dynamic behavior of the system, respectively, but mainly focused on the parts of interest from a forensic point of view.
Following the best software engineering practices, we have designed our framework to make extension as easy as possible to any IM application, allowing IM Artifact Finder to ignore the knowledge of internal details of each supported application.
This analysis phase is fully automated, so this methodology is scalable as IM Artifact Finder will retrieve memory artifacts without manual intervention, regardless of the number of conversations, users, or messages stored in RAM.
Reporting Phase
When IM Artifact Finder is used as a command line tool, it will generate a report containing information about the artifacts that were found. On the other hand, if it is used as a library, the creation of the report is optional, depending on whether the user wants to create it or not. By default, the generated reports are in JSON format, a commonly used open standard file format for data exchange. Currently, this is the only supported format for the report data. We have also designed IM Artifact Finder to make adding new report formats as easy as possible.
Getting a report in JSON format with all the memory artifacts found allows other applications to analyze it and process the information to, for example, search for specific words in conversations, or find all messages sent by a specific user. These reports can also be analyzed by a person and are formatted accordingly to improve readability.
Case Study: Telegram Desktop
As we commented above, we have used the Telegram Desktop application as a case study. In particular, we consider version 2.7.1 of Telegram Desktop for Windows systems.
Extension of IM Artifact Finder
We performed an initial automatic analysis to obtain a class diagram of the Telegram Desktop source code using Visual Paradigm. This automated process gave us a general idea of how the application is structured. After obtaining the entire class diagram, we identified in it the elements that we considered more relevant for a forensic investigation, and then we manually analyzed the source code of those elements in detail.
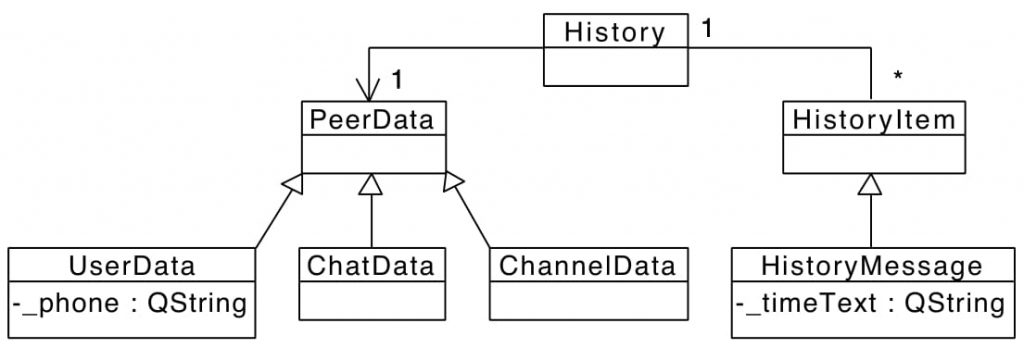
The PeerData class represents a conversation. The UserData class represents both a Telegram user and a one-on-one conversation. On the other hand, ChatData models a group and ChannelData a channel. The HistoryMessage class represents a message and the History class relates each message to its corresponding conversation.
The UserData class has the _phone attribute, which is the number of the mobile phone associated with the user’s account. Therefore, to find UserData objects in a memory dump we look for patterns of phone numbers. The _phone attribute is of type QString, which is a class that belongs to Qt, a framework for creating cross-platform applications that run on computers, mobile devices, and embedded systems. Since Telegram Desktop uses Qt, other relevant information (such as user names or message contents, for instance) is stored in attributes of type QString. Therefore, we have studied in detail how objects of class QString are represented in memory.
In Telegram Desktop, we can see the time each message was sent. This information is stored in the _timeText attribute of the HistoryMessage class. Considering this, we look for time patterns to be able to find HistoryMessage objects present in a memory dump.
Once we find UserData and HistoryMessage objects in a memory dump, pointers to other objects can be identified within them. Since it is possible to navigate through RAM from one object to another (thanks to the output format provided by Windows Memory Extractor), additional related objects can be obtained. As we analyze the source code of Telegram Desktop, we know which pointers we have to follow to get objects that are relevant from a forensic point of view. As a result, we identify the sender of each message, the conversation to which each message belongs, and the account to which each conversation belongs, among other things.
All this information allow us to create new classes to extend the IM Artifact Finder framework. These new classes allow us to use IM Artifact Finder to automatically analyze memory dumps from the Telegram Desktop application, since the classes contain the source code needed to obtain the artifacts without manual intervention.
Evaluation
A brief summary of the results that we can obtain from the Telegram Desktop application are as follows (a more detailed explanation can be found on our DFRWS EU 2022 paper):
- Accounts: number of accounts added to the application and information about the account owner of each account (their identifier number), full name, phone number, and username).
- Conversations: conversations that the user has accessed (distinguishing the type of text conversation) and their content (text messages, message replies, and forwarded messages.), users (or a subset of them, in the case of groups) participating in conversations. The information retrieved is not entirely reliable, as it is not always correct and is sometimes incomplete.
- Users: information of users who share their phone number with the account owner and some users who do not (distinguishing whether or not a user is a contact with the account owner). We were also able to retrieve contacts after deleting them.
- Privacy: we cannot find the phone number of a user if the user does not share their phone number. As a result, we conclude that Telegram only sends phone number information of users to whom it has permission to view it (as expected).
- Multimedia: files attached to a message (with its name and type), name and phone number of shared contacts, latitude and longitude of each transmitted geographic location (and other additional information, such as the name of the place or its address as they can appear as text accompanying the location).
- Locking: when the application is locked, we can retrieve the same information from the memory as when it is not locked. Although we were able to manually find the password located in the memory after unlocking the app, we have not been able to find it programatically. Also, we have empirically tested that the password is no longer present in the memory after a short period of time.
- Session: information about accounts, conversations, and users are retrieved after logging out, although the number of artifacts retrieved was always less than the number of artifacts retrieved before logging out. Also, the retrieval of memory artifacts after logging out is not completely reliable, as sometimes some of the information retrieved is incorrect or incomplete.
Final Discussion
The fact that the aforementioned information can be retrieved from the memory of the Telegram Desktop application means that, although its local database is encrypted and communications with the Telegram servers are also encrypted, a forensic analyst will be able to obtain valuable artifacts from the memory of a computer where Telegram Desktop is running.
Among others, knowing the information about the account owner can help identify the person to whom the seized computer belongs. Also, the possibility of knowing the conversations that users have accessed can be relevant to know what they were doing or with whom they were communicating moments before a certain event occurred.
Although retrieving conversations after deletion and retrieving artifacts after logging out are not completely reliable processes, a substantial part of the information obtained in our experiments was accurate. This can be very helpful to a forensic analyst, as this information is not accessible through the Telegram Desktop GUI. Similarly, a forensic analyst can reliably obtain valuable information from a seized computer when the Telegram Desktop application is running and locked.
And that’s all, folks! In this blog post we have summarized our paper entitled “Extraction and Analysis of Retrievable Memory Artifacts from Windows Telegram Desktop Application”, presented at DFRWS EU 2022. In the published paper you can find a more detailed explanation of the analysis environment we created and the experiments we carried out. Feel free to download, use, and extend the tools we developed! Thanks for reading! 🙂