
TL;DR Adversarial Domain Generation Algorithms (DGAs) let botnets craft domain names that evade Machine Learning (ML)-based detectors. The field lacks a common evaluation setup: models are tested on different datasets and metrics, and their code is rarely published, which makes comparing them hard. In our poster paper at DIMVA 2026, “The Simpler, the Stealthier: A Framework for Evaluating Adversarial Domain Generation Algorithm Models“, presented tomorrow, we release an open-source benchmarking framework that evaluates four adversarial DGA models (DeepDGA, CharBot, Deception, and MaskDGA) in a single environment across three dimensions: lexical characteristics, evasion against LSTM and CNN classifiers, and computational cost. In our experiments, the two simplest models, CharBot and Deception, evade detection over 75% of the time while training in under two seconds, while the two more complex models stay below 21% evasion despite needing hours of training. Interested? Keep reading this briefing or grab the code on GitHub.
Why Comparing Adversarial DGAs Is So Hard
Modern malware relies on DGAs to dynamically generate large volumes of pseudo-random domain names, giving botnets resilient command-and-control (C2) channels that resist static blocklists. Defenders responded with ML-based detectors that learn character-level patterns to flag Algorithmically Generated Domains (AGDs). Attackers then started crafting domains that mimic legitimate traffic to evade those detectors.
In our recent systematic literature review of this arms race, we found two obstacles that hold back progress in the field:
- No common ground for comparison. Most adversarial models are evaluated in isolation, on heterogeneous datasets and with inconsistent metrics, so direct comparison between studies is hard.
- Low reproducibility. Only 12.50% of the reviewed studies released public artifacts, which makes independent validation difficult.
Without a shared, open evaluation harness, it is hard to tell whether a new adversarial DGA is a real improvement or an artifact of a favorable dataset.
The Solution: A Unified Benchmarking Framework
To address both problems, we release an open-source benchmarking framework that evaluates adversarial DGA models in a single environment. The framework does not propose a new evasion technique. It provides a shared setup in which representative models receive the same data and are measured with the same metrics.
The framework is modular, with three decoupled layers coordinated by an orchestrator:
- A generation layer that groups the adversarial DGA models.
- A detection layer with the trained ML classifiers.
- An analysis layer that computes lexical statistics, detection metrics, and timing.
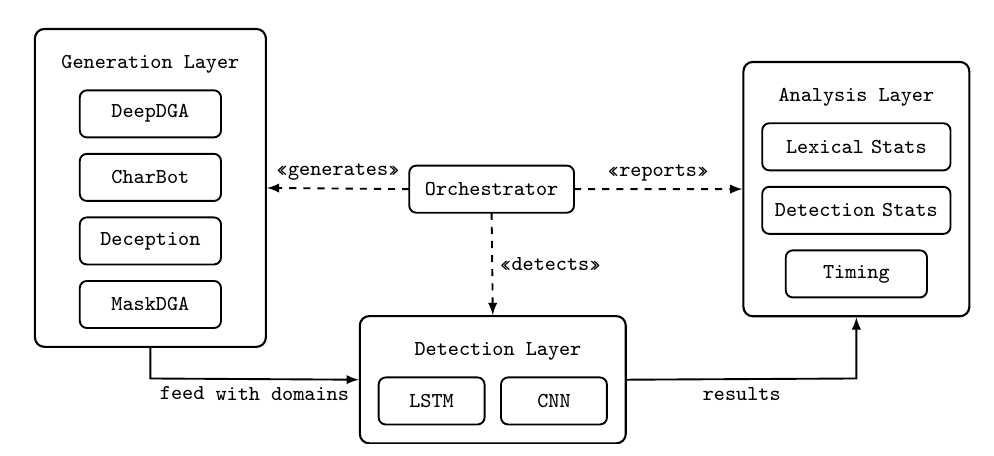
Inside the Framework
Datasets. We build three disjoint datasets from the Tranco list (benign domains) and DGArchive (malicious AGDs), each with a distinct role: D1 trains the adversarial models, D2 trains the detectors, and D3 acts as the control and evaluation set. D1 and D2 draw equally from the 58 DGA families with at least 50,000 samples each (100,000 malicious and 100,000 benign domains per dataset), so models and detectors see the full diversity of DGAs. D3 is restricted to four families representing distinct generation schemes, which enables a per-family comparison: Qakbot and Rovnix (arithmetic-based), Suppobox (dictionary-based), and Dyre (hash-based).
Adversarial models. We implement four representative models, DeepDGA, CharBot, Deception, and MaskDGA, plus two control groups: a malicious baseline of real AGDs from the four D3 families, and a benign baseline of real Tranco domains. The baselines are the reference points the adversarial models try to avoid (malicious) or mimic (benign).
Detectors. Two ML detectors trained on D2: an LSTM, a recurrent classifier at the character level, and a CNN, a convolutional classifier over character n-gram embeddings.
Metrics. For every model and control group, the analysis layer computes six lexical features (Shannon entropy, vowel ratio, digit ratio, unique-character ratio, maximum number of consecutive consonants, and length) along with training and generation times. Detection is measured with the evasion rate: the fraction of adversarial domains incorrectly classified as benign by each detector.
Key Findings: The Simpler, the Stealthier
We evaluated each model across three dimensions.
Lexical features. CharBot and Deception closely match the benign baseline across all metrics, particularly Shannon entropy, vowel ratio, and domain length, which suggests they learn the lexical distribution of legitimate domains. MaskDGA shows a profile closer to arithmetic DGA families, with lower vowel ratios and longer domains. DeepDGA is a clear outlier, with a mean length of 62 characters, a near-zero vowel ratio, and the highest digit ratio of any group.
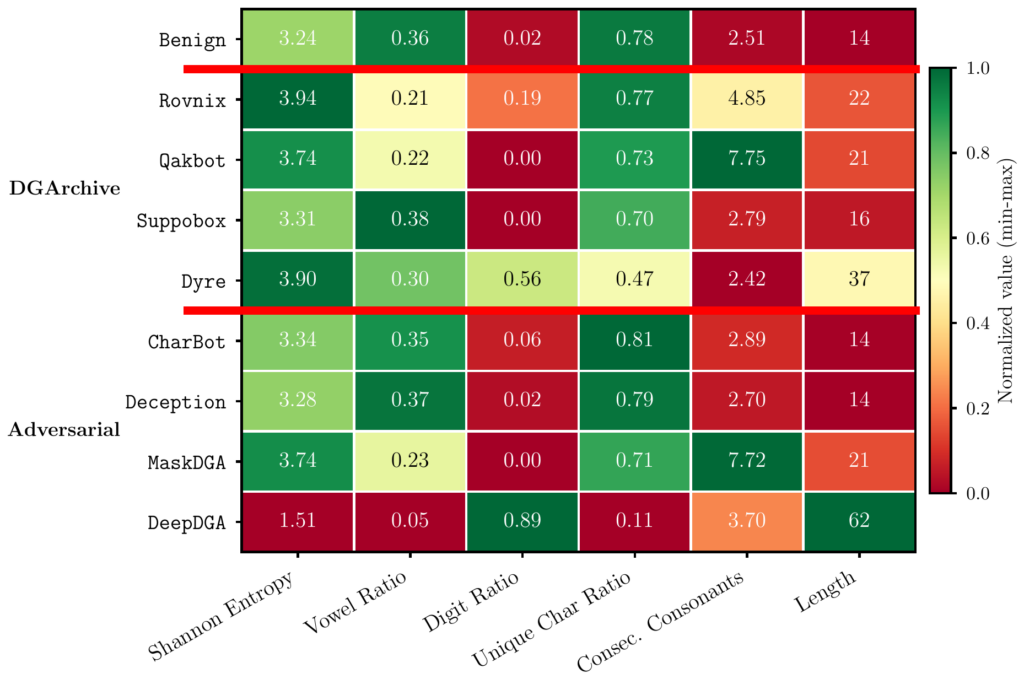
Detection evasion. Against benign domains, both detectors reach evasion rates above 96%. On real-world families, results depend on the generation scheme: hash-based Dyre is detected almost completely (evasion close to 0%), arithmetic Rovnix and Qakbot stay below 13%, and dictionary-based Suppobox is the hardest real family (64% against the CNN, 94% against the LSTM). Among the adversarial models, CharBot and Deception reach the highest evasion rates, above 75% and 84% respectively against both detectors. MaskDGA and DeepDGA stay below 21% in all cases, consistent with their divergent lexical profiles.
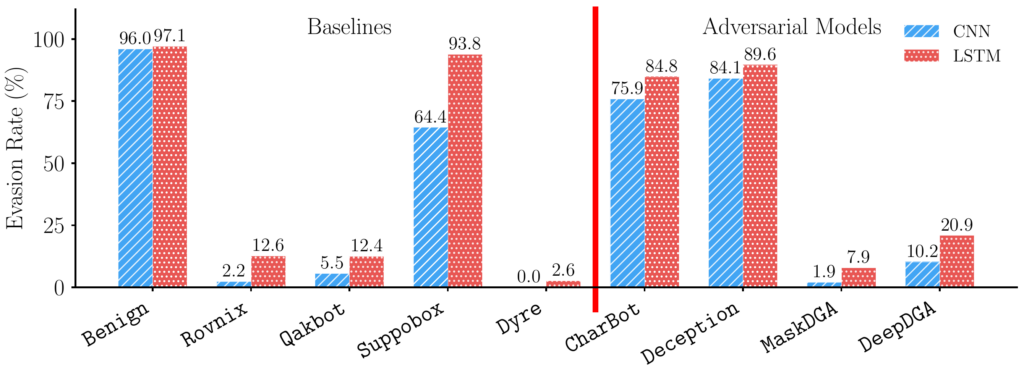
Computational cost. CharBot and Deception train in under two seconds and generate domains in microseconds. MaskDGA and DeepDGA need 2.61 and 21.11 hours of training respectively, and reach the lowest evasion rates in the study.
CharBot | Deception | MaskDGA | DeepDGA | |
|---|---|---|---|---|
| Training time (s) | 0.91 | 1.52 | 9,409 | 75,994 |
| Generation time (s/domain) | 10⁻⁵ | 10⁻⁴ | 0.056 | 0.11 |
Across the three dimensions, lexical similarity to benign domains, rather than model complexity, is what tracks with evasion success in our experiments. In this set of models, higher computational cost did not translate into higher evasion. This is the observation behind the paper’s title.
Takeaways for Defenders
- Model complexity is not a good proxy for risk. In our results, the two models that were cheapest to train were also the most evasive.
- Dictionary-based and benign-mimicking generators are the ones that evade detectors relying on surface statistics such as entropy or n-gram distributions.
- Shared benchmarks and open artifacts make it possible to compare techniques fairly and to reproduce results. We release the framework as open source for that reason.
Ongoing Work
This poster is a proof of concept for a broader study. We are extending the framework to cover all adversarial models identified in our systematic literature review, with additional lexical features (n-gram distributions), more detectors, and memory-usage profiling. We also plan to compare the numbers reported in the original papers with those obtained under our framework, and we are exploring a new adversarial model based on lightweight LLMs.
Funding Acknowledgments
This research was supported in part by grant PID2023-151467OA-I00 (CRAPER), funded by MICIU/AEI/10.13039/501100011033 and by ERDF/EU, by grant Programa de Proyectos Estratégicos de Grupos de Investigación (DisCo research group, ref. T21-23R), funded by the University, Industry and Innovation Department of the Aragonese Government. The work of Tomás Pelayo-Benedet was supported by the Government of Aragón through the Diputación General de Aragón (DGA) Predoctoral Grant, during 2025-2029.


And that’s all, folks! In the meantime, we encourage you to read the full poster paper at DIMVA 2026, explore and contribute to the framework on GitHub, or reach out to us if you’re interested in collaborating on adversarial DGA evaluation, botnet detection, or reproducible security benchmarking. Thanks for reading, and stay secure!
Declaration of Generative AI Technologies in the Writing Process
During the preparation of this post, the authors used Claude (Claude Opus 4.8 model) to improve readability and language. After using this tool, the authors reviewed and edited the content as necessary and take full responsibility for the content of this publication.