
TL;DR A common pitfall is to think that the content of a running process and its corresponding executable file (i.e., the content of the file stored on the disk) are identical. However, this is not true, as activities such as memory paging or relocation can affect to the binary code and data of a program file when mapped into memory. We have developed two methods to pre-process a memory dump to facilitate, by undoing the relocation process, the comparison of running processes and modules. We have implemented these methods as a Volatility plugin, called Similarity Unrelocated Module (SUM), which has been released under GNU Affero GPL version 3 license. You can visit the tool repository here.
Memory forensics is a branch of the computer forensics process focused on the recovery of digital evidence from computer memory, normally carried out as part of the detection and analysis stage in an incident response process. Memory forensics is of interest in scenarios where encrypted or remote storage media are used, as enables a forensic examiner to retrieve encryption keys or to analyze malicious software (malware) that solely resides in RAM.
In memory forensics, the current state of the system’s memory is acquired and saved to disk as a memory dump file, which is later taken off-site and analyzed with dedicated software such as Helix3, Rekall, or Volatility. Among other items (such as logged users or open sockets), a memory dump contains data regarding the running processes in the system at the acquisition time.
An important part of memory forensics is to distinguish between well-known and benign versus unknown and suspicious processes. Cryptographic hash functions (or one-way functions) such as MD5 or SHA-256, commonly used for data integrity and file identification of a seized device are unsuitable for identifying processes that belong to the same binary application, but in different executions, due to their avalanche effect property, which guarantees that the hash values of two similar, but not identical, inputs (e.g., inputs where only a single bit has been flipped) produce radically different outputs.
This is mainly motivated by the differences of the content of a running process and its corresponding executable file, caused by the OS loader when the executable file is mapped into memory prior execution. Memory alignment issues can cause the in-memory file to have a bigger size than its on-disk file. The memory subsystem OS manager normally uses a (small) granularity of 4KiB for every memory page allocated by a process. Similarly, the relocation process can slightly change the binary code of a process, especially in 32-bit scenarios.
So, can we overcome these limitations? Yes! Instead of cryptohash functions, we can rely on similarty digest algorithms, a subtype of approximate matching algorithm that provide a similarity score between two digests (the representation of two digital artifacts), normally in the range of [0, 100] rather than a binary value (yes/no).
In this series of blog posts, we introduce the methods proposed in our recent publication in Computers & Security to pre-process a memory dump and obtain more accurate similarity scores between modules contained in memory dumps. In particular, we have proposed two methods that identify and undo the effect of relocation. In this blog post, we only introduce one of them, Guided De-relocation, which relies on specific structures of the Windows PE format. The other method will be introduced in the next blog post (stay tuned!).
The Windows PE Format
Before continuing, we need you to know a little bit about the Windows PE format. The Windows Portable Executable (PE) format is the standard format used by Windows to represent executable files. Introduced from WinNT 3.1, it was the replacement for the previous executable format, the Common Object File Format (COFF). Interestingly, COFF was also used on the Unix-based systems before being replaced by the current format of executable files, the Executable and Linkable Format (ELF).

The Windows PE format is composed by different parts (see the image above). First, there are the MS-DOS headers for backward compatibility. Then come the PE/COFF headers, which include the magic bytes of the PE signature as an ASCII string (“PE” followed by two null bytes), the PE file header, and optionally the PE optional header. This header is only optional for object files, and is always present for executable files. The optional header includes important information as a structure named DataDirectory, which contains relevant data such as the export and import directories of the program binary, as well as its relocation table, stored in a .reloc section within the PE format. After the PE/COFF headers appear the Section headers. For every section contained within the program binary, a section header exists which defines the section size in the binary file as well as in the memory and other file characteristics. Finally, the content of each section follows as a linear byte stream. The starting and ending limits of every section are defined in each section header.
The .reloc section, added to a program binary by the compiler, contains the necessary information to allow the Windows PE loader to make any adjustment needed in the program binary code and data of the application due to relocation. The information of this section is divided into blocks, where each block represents the adjustments needed for a 4KiB memory page. Every block contains an IMAGE_BASE_RELOCATION structure, which contains the relative virtual address (RVA) of the page and the block size. The block size field is then followed by any number of 2-byte entries (i.e., a word size), which codifies a value that indicates the type of base relocation to be applied (first 4 bits of the word) and an offset from the RVA of the page that specifies where the base relocation is to be applied (the remaining 12 bits).
Guided De-relocation Pre-Processing Method
The information of .reloc section is processed by the Windows PE loader when a program binary is loaded into memory to resolve any adjustment needed due to relocation. Once the program binary has been appropriately relocated, this section is stripped off from the image file (the representation of the program file in memory). So, have we already lost the game? Not yet!
Luckily, a memory dump may contain other elements rather than the image file that represent the image file and do contain such a .reloc section, such as File Objects. This structure represents the files mapped into the kernel memory, and acts as the logical interface between the kernel and the user-space and the corresponding data file stored in a physical disk.

In addition, this kernel-level structure contains a pointer to another structure which in turn is made up of three opaque pointers: DataSectionObject, SharedCacheMap, and ImageSectionObject. An opaque pointer points to a data structure whose contents are unknown at the time of its definition. From these structures, both DataSectionObject and ImageSectionObject may point to a memory zone
where the program binary was mapped either as a data file (i.e., containing all its content as in the program binary itself) or as an image file (that is, once the Windows PE loader has relocated it). Both memory representations contain the .reloc section of the program binary. Hell yeah, we got it!
The algorithm of our Guided De-relocation pre-processing method is shown below. Using the Volatility plugin filescan we find the FileObjects presented in a memory dump and we then iterate on every module (retrieved with the Volatility plugin modules) that has a FileObject structure associated to it. We finally navigate through the .reloc section and undo the relocation to every block entry. The unrelocation process is performed by zeroing the most significant bytes of the memory addresses (two bytes for 32-bit processes, and six bytes for 64-bit processes), as we assume that the relocation process takes place with 64KiB alignment, as ASLR does. A more in-depth description of the steps of the algorithm is given in the paper (check the pre-print here).

Evaluation
In the paper, we have extensively evaluated this pre-processing method considering three versions of Windows (Windows 7, Windows 8.1, and Windows 10) in both 32-bit and 64-bit architectures, running on top of the VirtualBox hypervisor. For comparison, we have selected three sets of modules such that they have a .reloc section: system libraries, which are used in almost all processes (we chose ntdll.dll, kernel32.dll, and advapi32.dll); system programs, which are system processes common to all Windows OS considered in the evaluation (we chose winlogon.exe, lsass.exe, and spoolsv.exe); and workstation programs , which include common workstation software such as Notepad++version v7.5.8 and vlc version 3.0.4. We have used four approximate matching algorithms for comparison: dcfldd, ssdeep, sdhash, and TLSH.
For every memory dump, we extracted these modules and computed the similarity hashes under three scenarios:
no pre-processing (Raw scenario), applying the Guided De-relocation pre-processing method (Guided De-relocation scenario), and applying the Linear Sweep De-relocation method (Linear Sweep De-relocation scenario; the other pre-processing method that we have proposed, it will be explained in the next blog post).
For the sake of brevity, we only show here the related comparison evaluation, in which we compare valid (i.e., non-null) memory pages in the same relative offset, using the same pre-processing method. An interesting reader is referred to the paper for more experimental evaluation and further discussion.
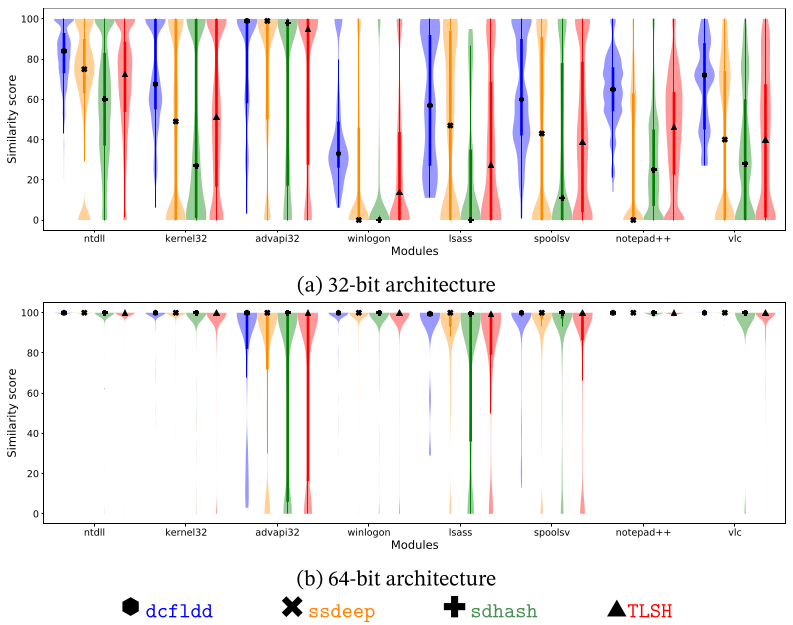
The figure above shows the aggregated similarity scores of the Raw scenario as violin plots, which show the median as an inner mark, a thick vertical bar that represents the interquartile range, and the lower/upper adjacent values to the first quartile and third quartile (the thin vertical lines stretching from the thick bar). As shown, the similarity scores in 32-bit are more disperse and the lower/upper adjacent values are normally all in the range of possible scores, independently of the module or the algorithm.
The results in 64-bit architecture are more stable than in 32-bit architecture. Note that the median of the similarity score is near to 100 for all algorithms and all modules. Only the lower adjacent values of advapi32.dll, lsass.exe, and spoolsv.exe have a wider interval. We have manually checked these results and found that they are due to the modules retrieved from Windows 8. In particular, the dissimilar bytes are caused by lookup tables within the code section of the modules.
These good results for 64-bit architecture may be due to the new addressing form introduced with the 64-bit mode in Intel, RIP-relative addressing, which guarantees that no assembly instruction incorporates an absolute memory address within the binary representation of the instruction itself.
See now how the things change when the Guided De-relocation pre-processing method is applied in the next figure. The results show that the Guided De-relocation pre-processing method performs particularly well, having the median values at the top of the plots for every algorithm and every module in both architectures. Some outside values appear in the case of sdhash, motivated by its way of working: sdhash requires at least 16 features to compare a digest, otherwise the similarity score is zero. Pages with low entropy usually yield less than 16 features. For example, the last page of a sections because they are filled with zeros to pad the difference between the size on disk and the size on memory.
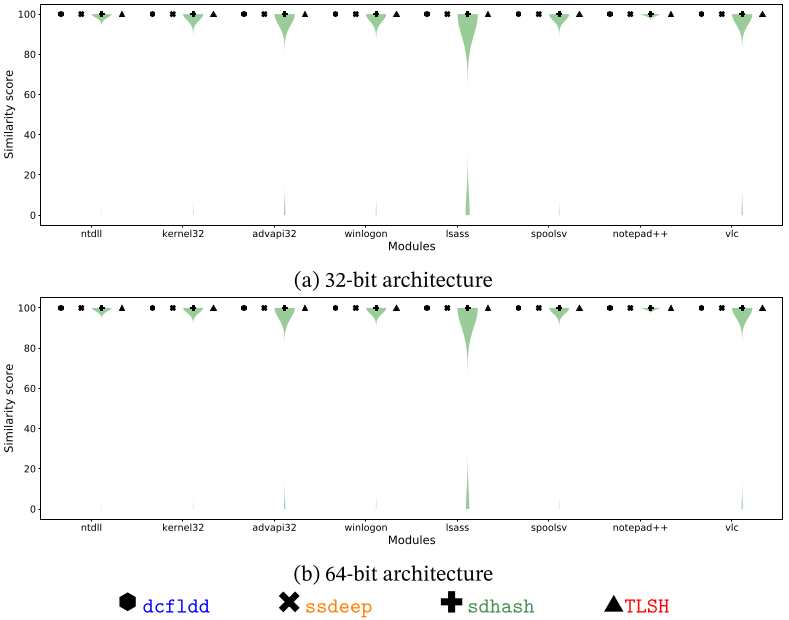
Note that after applying the Guided De-relocation pre-processing method there are still differences among certain memory pages. However, the percentage of these memory pages is quite low (only 180 out of the 2,327,720 comparisons performed). Furthermore, we have empirically observed that almost all of them occurred in the first memory page of the code section, due to the changes caused by the Import Address Table (IAT) of the module that unfortunately is not covered by the .reloc section.
Tool implementation
We have implemented both pre-processing methods in a plugin for the Volatility memory analysis framework. Our plugin, called Similarity Unrelocated Module (SUM), is an improvement of our previous tool ProcessFuzzyHash. SUM have been released under GNU Affero GPL version 3 license and is available in GitHub.
SUM yields a similarity digest for every valid memory page from every module which is retrieved from a memory dump, while the comparison is an array of similarity scores by pages. The forensic analyst can choose to pre-process every module with the Guided De-relocation method only (when the .reloc section is retrievable), with the Linear Sweep De-relocation method only, or with both (it first tries to recover the .reloc section to apply the first pre-processing method, and applies the second method if it fails). By default, SUM applies no pre-processing method.
The plugin also supports the use of more than one similarity digest algorithm at once, the selection of only specific sections of the modules for similarity comparison, and selecting processes by PID or processes and shared libraries by name.
If you have read up to here, congratulations! :). We hope you have a more clear concept on the issues faced in memory forensics and triage of running processes at the acquisition time. In our next blog post, we’ll present the other pre-processing method presented in our paper, the Linear Sweep De-relocation method. Stay tuned!
1 Pingback