
TL;DR A common pitfall is to think that the content of a running process and its corresponding executable file (i.e., the content of the file stored on the disk) are identical. However, this is not true, as activities such as memory paging or relocation can affect to the binary code and data of a program file when mapped into memory. We have developed two methods to pre-process a memory dump to facilitate, by undoing the relocation process, the comparison of running processes and modules. We have implemented these methods as a Volatility plugin, called Similarity Unrelocated Module (SUM), which has been released under GNU Affero GPL version 3 license. You can visit the tool repository here.
In a previous post we have already motivated this research, as well as giving some background on the Windows memory subsystem and the Windows PE format. Furthermore, we also explained the Guided De-relocation process, which is a method to identify and undo the effect of relocation relying on specific structures of the Windows PE format. In particular, the Guided De-relocation process uses File Objects, a kernel-level structure that represents the files mapped into the kernel memory. You can read more on this method in our previous blog post or in our recent publication in Computers & Security. In this post, we are going to introduce the other method, named Linear Sweep De-relocation.
Linear Sweep De-relocation Method
Unlike Guided De-relocation, this method works independently from the File Object structures. Therefore, it can be applied to any module in a memory dump, regardless there is a File Object that represents such a module.
The algorithm of this pre-processing method is giving below. In summary, the algorithm works in all bytes of a module in two phases. The first phase is devoted to analyze structured data, i.e., all the bytes of the PE header and the data directories are processed, looking for memory addresses to de-relocate them, if needed. At the same time, these bytes are tagged as visited. Recall that this de-relocation process consists in leaving the two-less significant bytes unmodified, while zeroing the others (two bytes for 32-bit processes, and six bytes for 64-bit processes).

The second phase is devoted to unstructured information. First, the bytes of the lookup tables are tagged as visited. Byte patterns and strings are tagged next. Finally, the rest of bytes that have not been visited are processed. For every non-visited byte, we build sequences (in bytes) of valid assembly instructions. In this regard, we get slices of the contiguous 15 bytes starting at the address of b, considering the maximum length of Intel assembly instruction. Our algorithm processes these sequences in an optimized way to avoid redundant disassembling. In particular, we iterate in each instruction of the sequence, marking the beginning of every instruction in an auxiliary structure until we detect an instruction which was previously marked as the beginning of an instruction in another sequence. In such a case, we discard the current sequence of instructions since we have reached a subsequent sequence of instructions already recognized by another previous sequence of instructions and thus, the previous sequence will always be greater in length than the current one. We rely on the Capstone disassembly framework to obtain the valid sequences of instructions.
Finally, we select the longest byte sequence of valid assembly instructions and iterate in each instruction in this sequence, tagging every byte of the instruction as a visited
byte and checking if it contains an instruction that has an operand which is a memory address. If so, the de-relocation process takes place.
Let us illustrate how the processing of sequences of instructions works by providing an example. Assume the following snippet of real assembly code of a Windows library (instructions are shown in hexadecimal representation and in mnemonics) whose bytes were not identified by any of the previous steps of the algorithm:

Consider now a slice of 15 bytes. We start disassembling at the byte 0xFC, getting the code snippet:

This sequence is only 1-byte long, as the next byte is not a valid instruction. We then update the auxiliary structure indicating that the sequence starting at the byte 0xFC is 1-byte long and ends in the byte 0xFE (value -1):

The sequence starting at the next bytes are also invalid, till the byte 0xE8. Starting at this byte, we obtain the following code snippet:

This sequence is 17 bytes long, so the corresponding position is updated in the auxiliary structure appropriately. Note that the starting bytes of other instructions are marked with a value -1:

The code snippet starting at the byte 0x39 has an instruction which was already part of a previous snippet, as indicated by the value -1 found on the structure:

Therefore, the processing of this code snippet is skipped and discarded. The auxiliary structure is updated appropriately:

This process iteratively repeats until the end of the sequence. The auxiliary structure is finally as:

In this case, the longest sequence found was the one starting at the byte 0xE8. The bytes in the slice are marked as visited, and if any instruction has a memory operand targeting the virtual memory range of the process, its address is de-relocated. Now, the next slice would start at the byte 0xFE (in address 0x1016), which is the end of the longest sequence found.
Evaluation
A brief explanation of our experimental scenarios is given in our previous post. For the sake of brevity, we refer the reader to the previous post or to the paper for more experimental evaluation and further discussion.
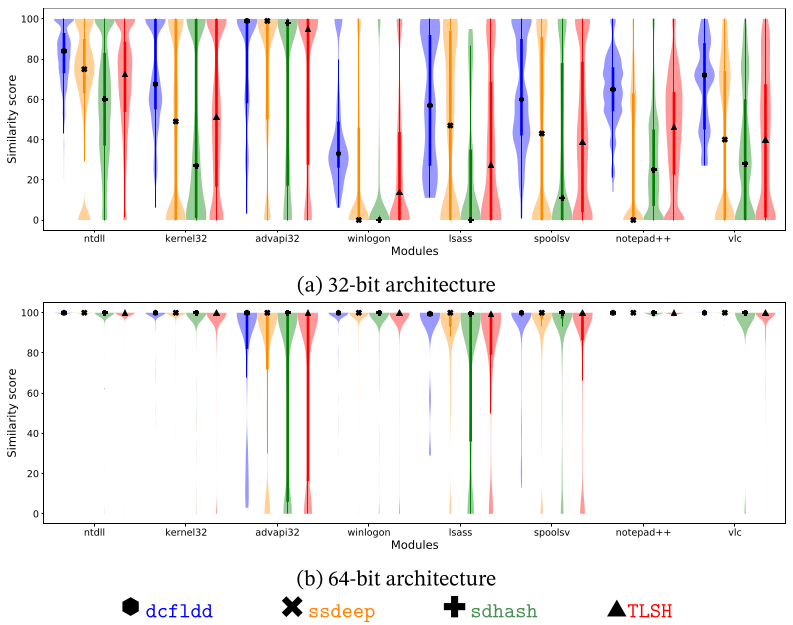
The figure above shows the aggregated similarity scores of the Raw scenario as violin plots, which show the median as an inner mark, a thick vertical bar that represents the interquartile range, and the lower/upper adjacent values to the first quartile and third quartile (the thin vertical lines stretching from the thick bar). As shown, the similarity scores in 32-bit are more disperse and the lower/upper adjacent values are normally all in the range of possible scores, independently of the module or the algorithm.
The results in 64-bit architecture are more stable than in 32-bit architecture. Note that the median of the similarity score is near to 100 for all algorithms and all modules. Only the lower adjacent values of advapi32.dll, lsass.exe, and spoolsv.exe have a wider interval. We have manually checked these results and found that they are due to the modules retrieved from Windows 8. In particular, the dissimilar bytes are caused by lookup tables within the code section of the modules.
These good results for 64-bit architecture may be due to the new addressing form introduced with the 64-bit mode in Intel, RIP-relative addressing, which guarantees that no assembly instruction incorporates an absolute memory address within the binary representation of the instruction itself.
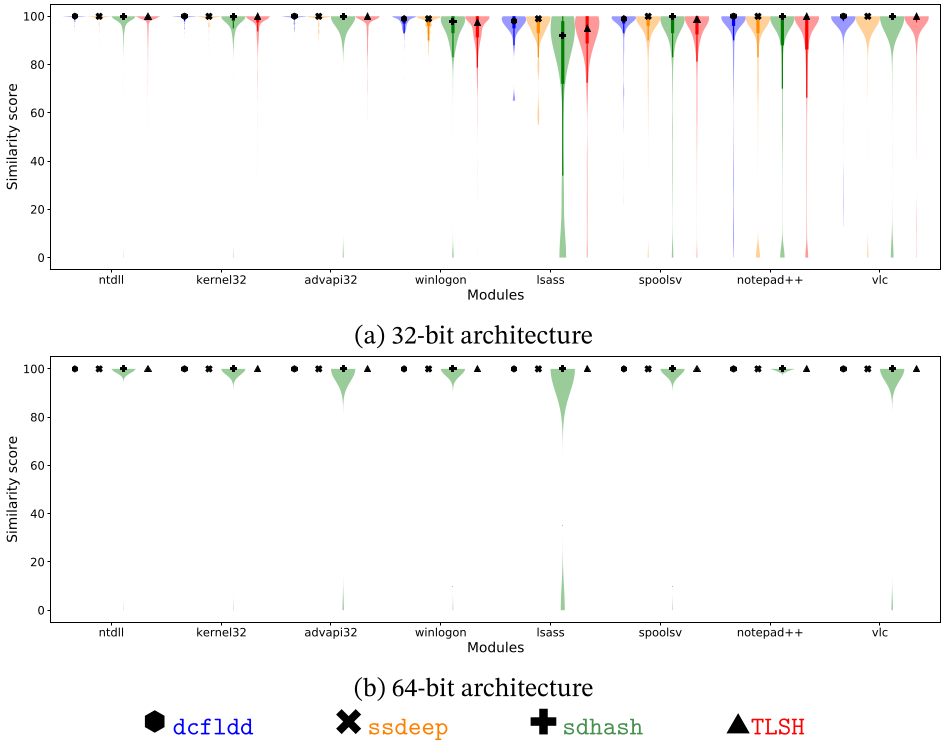
When the Linear Sweep De-Relocation pre-processing method is applied, the results vary significantly. As shown below, the results of the similarity scores are extremely good. Note that this method is even better than the Guided De-relocation pre-processing method, as it can be applied to all modules within a memory dump, and not only the ones with their corresponding File Objects being placed in memory. Regarding the 64-bit scenario, the results in the case have almost perfect similarity, having some outsider values in the case of the sdhash algorithm. As before, these almost perfect results may be motivated due to RIP-relative addressing of Intel x64.
Tool implementation
As we have explained in our previous post, both pre-processing methods are implemented in a plugin for the Volatility memory analysis framework. Our plugin, called Similarity Unrelocated Module (SUM), is an improvement of our previous tool ProcessFuzzyHash. SUM have been released under GNU AGPL version 3 license and is available in GitHub.
And that’s all, folks. This post closes our series on the two de-relocation processes that we have presented in our recent paper in COSE. Feel free to use our plugin and send us your impressions and even ideas for improvement. We will be delighted to keep improving our tool and keep researching on this area of memory forensics!